









网站 robots.txt 文件配置方法,如何禁止搜索引擎收录指定网站某一篇超链接地址呢,今天跟着麦站一起学学吧。
搜索引擎通过网络蜘蛛抓取网页的内容,并展示在相关的搜索结果中。但是有些网页内容我们可能并不想被搜索引擎收录和索引,如管理员后台等。
我们就可以通过 robots.txt 文件来声明允许/禁止搜索引擎的蜘蛛抓取某些目录或网页,从而限制搜索引擎的收录范围。

什么是 robots.txt
Robots是站点与spider沟通的重要渠道,站点通过robots文件声明本网站中不想被搜索引擎收录的部分或者指定搜索引擎只收录特定的部分。
Robots.txt用法:
User-agent:用于指定指令所作用于的目标抓取工具(网络蜘蛛),后接抓取工具名称;
Disallow:指定不允许抓取的目录或网页,后面为空则表示允许抓取一切页面;
Allow:指定允许抓取的目录或网页;
Sitemap:站点地图的位置,必须是绝对路径;
*:表示通配符;
$:表示网址结束;
/:匹配根目录以及任何下级网址。
禁止抓取某一个超链接:
Disallow: /news/hangyejishu/43.html
robots.txt文件用法举例
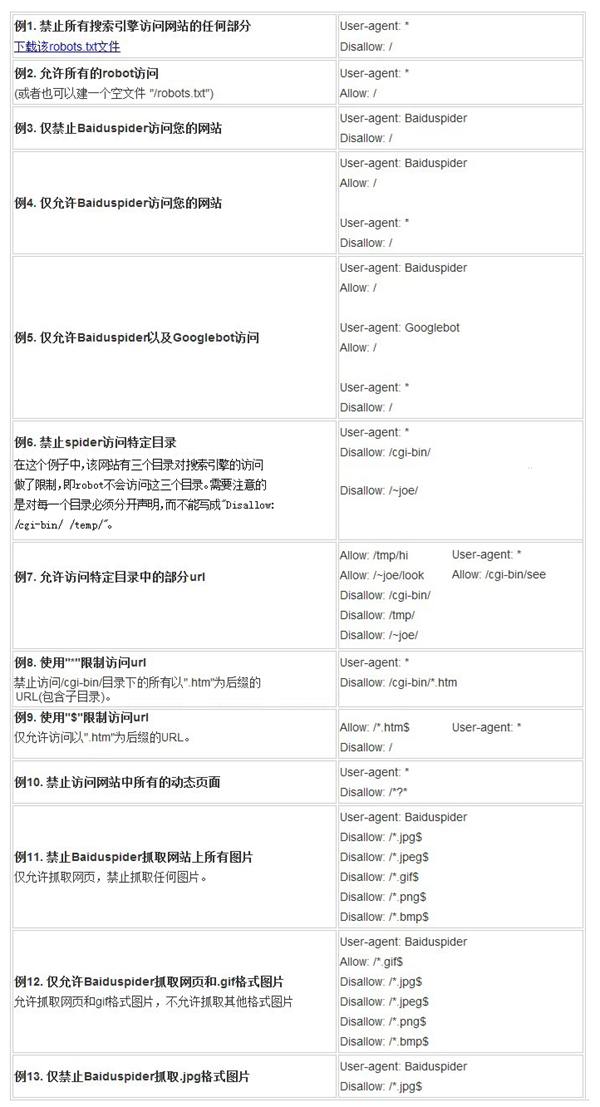
Robots.txt工具:
http://tool.chinaz.com/robots/







发表评论
评论列表(0条)